Come detto precedentemente, il semantic web ha l’obiettivo di dare alle informazioni un significato, correlarle tra loro e rendere le informazioni machine-readable. Per mettere in pratica questo concetto è necessario un modello, una tecnologia che permetta di identificare le risorse, definirne il significato e le relazioni.
Lo standard W3C per la rappresentazione delle informazioni delle risorse sul web è il Resource Description Framework (RDF), il quale fornisce quindi un framework comune per esprimere i significati delle informazioni, ma anche per poterle renderle condivisibili tra le applicazioni, facendo sì che i dati possano essere disponibili anche per applicazioni diverse da quelle per cui erano stati originariamente creati.
Questo linguaggio, inteso per rappresentare metadati delle risorse sul web (ad esempio autore, titolo o data di creazione di una pagina web), può anche essere generalizzato per rappresentare informazioni riguardo entità che non sono necessariamente recuperabili o scaricabili dal web (pagine web, file, video, ecc…), ma anche entità che possono essere semplicemente identificate sul web (come ad esempio persone, eventi o informazioni riguardanti prezzi di prodotti su un negozio on-line), rendendo di fatto rappresentabile qualsiasi elemento.
L’RDF sfrutta gli identificatori Web URIs (Uniform Resource Identifiers) per identificare gli elementi e per descriverli fa uso di proprietà e relativi valori associati. Con questi principi di base, l’RDF può rappresentare definizioni delle risorse in forma di grafi, formati da nodi e archi che rappresentano le risorse, le loro proprietà e i rispettivi valori. Questo modello a grafi è codificato in un formato che utilizza una sintassi XML-based, chiamata RDF/XML, tramite la quale diventa possibile per le macchine elaborare il modello e comprendere il significato delle descrizioni delle risorse.
Per descrivere le risorse in RDF, vengono costruite delle frasi composte da:
– soggetto, la parte della frase che identifica la cosa descritta
– predicato, la parte che identifica la proprietà (della cosa) che viene specificata dalla frase
– oggetto, la parte che identifica il valore della proprietà
Questo tipo di struttura è la stessa che si può immaginare per una semplice frase in linguaggio naturale come:
“Questo blog è scritto da Simone Dezaiacomo”
in cui troviamo un soggetto della frase (Questo blog), un predicato, ovvero la proprietà che viene specificata (è scritto da, cioè chi ne è l’autore) e l’oggetto, ovvero il valore della proprietà (Simone Dezaiacomo).
Le frasi che descrivono le risorse in RDF non sono quindi nient’altro che semplici frasi così strutturate. Una frase di questo tipo può però, come ci si può immaginare, dare dei problemi nel caso in cui a leggerla non sia una persona, ma sia una macchina. Come fare quindi per rendere la frase machine-readable?
Per farlo sono necessari due elementi:
1) un sistema di identificatori machine-readable per rendere soggetto, predicato e oggetto identificabili univocamente
2) un linguaggio machine-readable per rappresentare la frase e scambiarle tra le applicazioni.
Nella nostra frase d’esempio, identificare univocamente il soggetto (il blog) è possibile utilizzando semplicemente l’URL, ma come identificare predicato e oggetto, che non sono risorse web e non possiedono quindi un URL?
Per farlo si usa appunto un identificatore più generico fornito dal web: l’URI (di cui gli URL sono un sottoinsieme), che ha la proprietà di poter essere creato da utenti per identificare le risorse, sia accessibili dalla rete che non (come nel caso delle persone o di concetti astratti come il possesso). Più precisamente gli identificatori utilizzati da RDF sono le URI references (URIref), ovvero identificatori formati da un URI cui è aggiunto un suffisso con caratteri UNICODE, rendendo così possibile rappresentare e definire le relazioni tra qualsiasi cosa.
Per quanto riguarda il secondo elemento fondamentale per rendere le frasi RDF machine-readable, il linguaggio, come si è accennato precedentemente RDF utilizza l’XML/RDF che definisce dei tag specifici per rappresentare le triple rendendole interpretabili correttamente dalle applicazioni scritte per farlo.
Il modello fondamentale di rappresentazione per le frasi RDF si è detto che sono i grafi RDF, che sono così rappresentati:
– nodo per il soggetto
– nodo per l’oggetto
– arco per il predicato, che unisce soggetto a oggetto

Grafo RDF per la frase: "Questo blog è scritto da Simone Dezaiacomo"
Gli oggetti (che rappresentano i valori associati ai predicati) possono essere rappresentati sia tramite URIref, sia come stringhe di caratteri (dette literals, che a loro volta possono essere plain o typed). Potrebbe sembrare più intuitivo identificare gli oggetti come literals (come nell’esempio qui sopra), poichè questi rappresentano dei valori. Ma non sempre questo ragionamento è corretto, in quanto identificare gli oggetti (ma lo stesso discorso vale anche per i predicati) con le URIref è utile sia per permettere alle applicazioni di distinguere le proprietà che potrebbero essere identificate con lo stesso nome literal (es: il literal “Nome” come nome di persona o come nome di variabile) ed è utile anche per far sì che le proprietà possano essere trattate come risorse a loro volta, dando la possibilità di associare loro informazioni aggiuntive. L’utilizzo degli URIref per soggetti, predicati e oggetti è importante per lo sviluppo e l’uso di vocabolari condivisi e ad esempio per permettere la scrittura di applicazioni che si comportano in un certo modo in base al significato che viene ricavato dall’elaborazione di un certo URIref.
Per rappresentare i nodi di un grafo che sono identificati da URIref si usano delle ellissi, mentre per quelli identificati da literals si usano rettangoli.
Un altro modello di rappresentazione per le frasi RDF è quello delle triple, in cui ogni frase è scritta come una tripla ordinata formata dai 3 elementi base: soggetto, predicato e oggetto, precisamente nella forma:
<soggetto> <predicato> <oggetto>
oppure
<soggetto> <predicato> “oggetto”, se l’oggetto è literal
Per la nostra frase d’esempio, avremo quindi:
<https://semanticweb30.wordpress.com> <http://purl.org/dc/elements/1.1/creator> “Simone Dezaiacomo”
Per frasi multiple relative allo stesso soggetto, ogni tripla rappresenta un arco del corrispondente grafo. Quindi se ad esempio abbiamo 3 frasi RDF con lo stesso soggetto, nel grafo troveremo il nodo di partenza (soggetto) da cui si dipartono più rami che rappresentano predicati e oggetti, mentre nelle triple avremo la ripetizione del soggetto in ognuna delle 3 frasi.

Grafo RDF frasi multiple sullo stesso soggetto
Le equivalenti triple saranno:
<https://semanticweb30.wordpress.com> <http://purl.org/dc/elements/1.1/creator> “Simone Dezaiacomo”
<https://semanticweb30.wordpress.com> <http://purl.org/dc/elements/1.1/language> “IT”
<https://semanticweb30.wordpress.com> <http://purl.org/dc/elements/1.1/contributor> <http://www.example.org/exblogger/1123>
La notazione delle triple può diventare scomoda a causa della lunghezza delle URIref utilizzate per identificare le risorse. Per abbreviarne la notazione, sono stati introdotti i QName, che sono formati da:
prefisso_assegnato_all’URI : local_name
potremmo quindi sostituire dc:creator al posto di <http://purl.org/dc/elements/1.1/creator>
Quindi l’URIref completo si può ottenere dall’URI associato al QName + il local name.

Grafo RDF con QNames al posto delle URIref
Esempi di QName e URI associati:
rdf: –> URI: http://www.w3.org/1999/02/22-rdf-syntax-ns#
rdfs: –> URI: http://www.w3.org/2000/01/rdf-schema#
dc: –> URI: http://purl.org/dc/elements/1.1/
owl: –> URI: http://www.w3.org/2002/07/owl#
Utilizzando quindi URIref al posto di stringhe per identificare le risorse, RDF deve riferirsi ad un insieme di URIref come vocabolario. Spesso le URIref nel vocabolario sono organizzate in modo da essere rappresentate come insiemi di QNames con prefisso comune; cioè può essere scelta una URIref comune per tutti i termini nel vocabolario e a questa viene aggiunto il local name. In questo modo un’organizzazione può ad esempio definire un vocabolario di URIref che iniziano con un certo prefisso (http://www.example.org/terms/) per i termini che usa nelle sue attività aziendali (data-creazione, prodotto, nome-prodotto; che diventeranno local names) e un altro vocabolario che inizia con un altro prefisso (http://www.example.org/staffid) per identificare gli impiegati. RDF stesso definisce in questo modo modo il suo proprio vocabolario di termini che hanno un significato specifico in RDF, questi URIref iniziano con il prefisso http://www.w3.org/1999/02/22-rdf-syntax-ns# cui è associato il QName rdf:
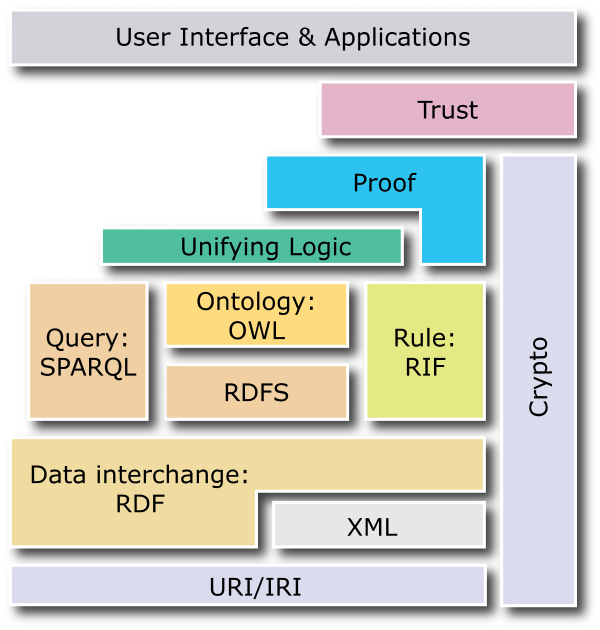
RDF, trattato qui sono nei suoi aspetti base, è solo uno degli elementi dell’architettura del semantic web, che possono essere rappresentati dal “layer-cake” diagram qui di seguito.

Layer Cake Diagram - W3C
Fonti:
http://www.w3.org/TR/2004/REC-rdf-primer-20040210/
http://www.w3.org/RDF/
http://www.w3.org/2001/sw/
http://www.w3.org/2001/11/IsaViz/
http://dublincore.org/documents/dces/






